DRaCoN
DRaCoN – Differentiable Rasterization Conditioned Neural Radiance Fields for Articulated Avatars#
Amit Raj, Umar Iqbal, Koki Nagano, Sameh Khamis, Pavlo Molchanov, James Hays, Jan Kautz
NeRF
SMPL
arXiv 2022
Abstract#
Acquisition and creation of digital human avatars is an important problem with applications to virtual telepresence, gaming, and human modeling. Most contemporary approaches for avatar generation can be viewed either as 3D-based methods, which use multi-view data to learn a 3D representation with appearance (such as a mesh, implicit surface, or volume), or 2D-based methods which learn photo-realistic renderings of avatars but lack accurate 3D representations. In this work, we present, DRaCoN, a framework for learning full-body volumetric avatars which exploits the advantages of both the 2D and 3D neural rendering techniques. It consists of a Differentiable Rasterization module, DiffRas, that synthesizes a low-resolution version of the target image along with additional latent features guided by a parametric body model. The output of DiffRas is then used as conditioning to our conditional neural 3D representation module (c-NeRF) which generates the final high-res image along with body geometry using volumetric rendering. While DiffRas helps in obtaining photo-realistic image quality, c-NeRF, which employs signed distance fields (SDF) for 3D representations, helps to obtain fine 3D geometric details. Experiments on the challenging ZJU-MoCap and Human3.6M datasets indicate that DRaCoN outperforms state-of-the-art methods both in terms of error metrics and visual quality.
PaperApproach#
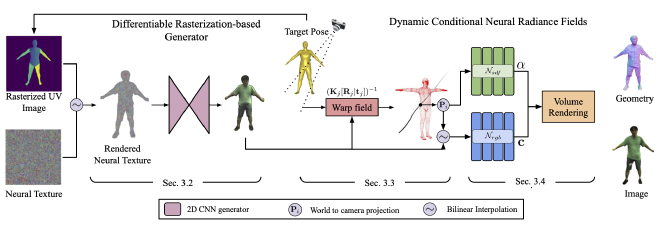
DRaCoN overview.Results#
Data#
![]()
![]()
Comparisons#
![]()
![]()
![]()
Papers Published @ 2022 - This article is part of a series.
Part 21: This Article