HumanRAM
HumanRAM: Feed-forward Human Reconstruction and Animation Model using Transformers#
Zhiyuan Yu, Zhe Li, Hujun Bao, Can Yang, Xiaowei Zhou
SMPL-X
Texture
Monocular
SIGGRAPH 2025
Abstract#
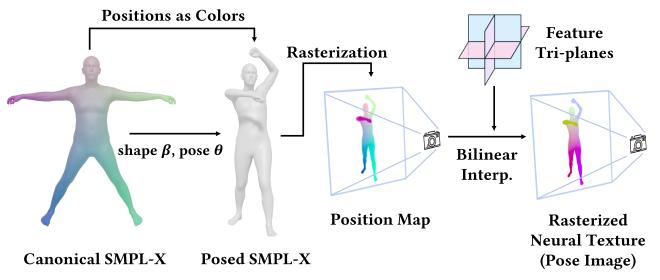
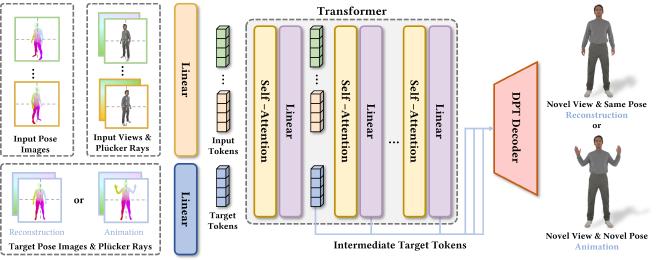
3D human reconstruction and animation are long-standing topics in computer graphics and vision. However, existing methods typically rely on sophisticated dense-view capture and/or time-consuming per-subject optimization procedures. To address these limitations, we propose HumanRAM, a novel feed-forward approach for generalizable human reconstruction and animation from monocular or sparse human images. Our approach integrates human reconstruction and animation into a unified framework by introducing explicit pose conditions, parameterized by a shared SMPL-X neural texture, into transformer-based large reconstruction models (LRM). Given monocular or sparse input images with associated camera parameters and SMPL-X poses, our model employs scalable transformers and a DPT-based decoder to synthesize realistic human renderings under novel viewpoints and novel poses. By leveraging the explicit pose conditions, our model simultaneously enables high-quality human reconstruction and high-fidelity pose-controlled animation. Experiments show that HumanRAM significantly surpasses previous methods in terms of reconstruction accuracy, animation fidelity, and generalization performance on real-world datasets.
PaperApproach#
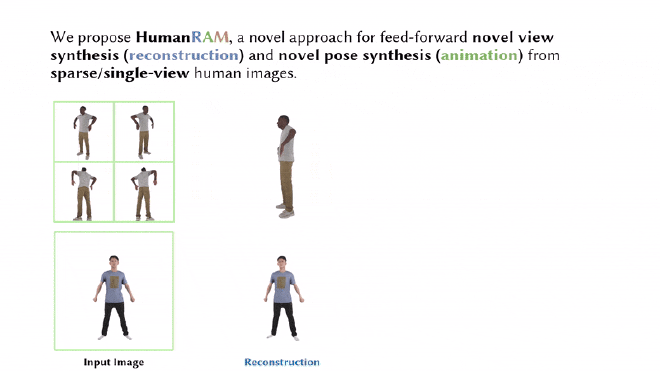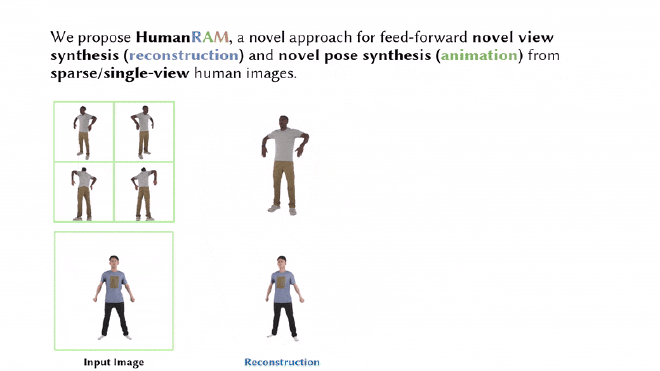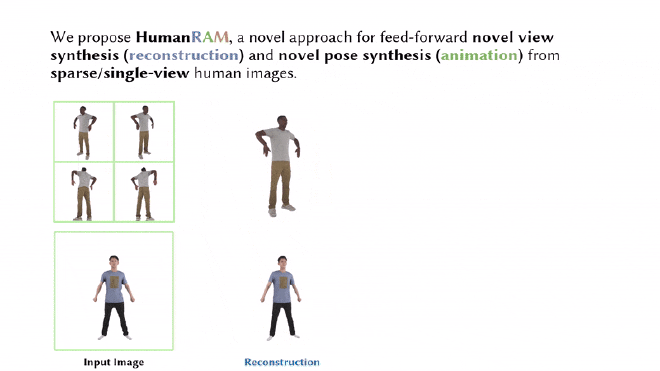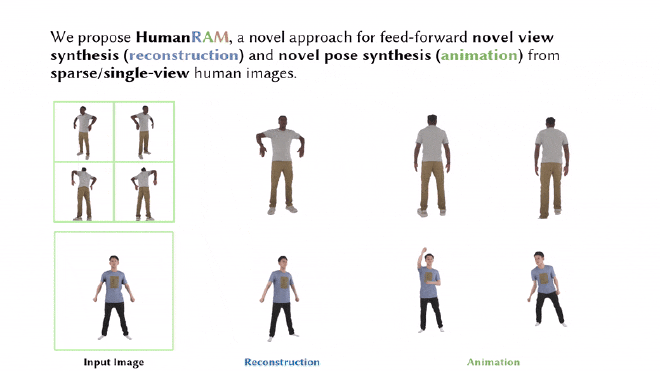
Results#
Data#
![]()
![]()
![]()
![]()
Comparisons#
![]()
![]()
![]()
![]()
Papers Published @ 2025 - This article is part of a series.
Part 22: This Article