NoPo-Avatar
NoPo-Avatar: Generalizable and Animatable Avatars from Sparse Inputs without Human Poses#
Jing Wen, Alexander G. Schwing, Shenlong Wang
Splats
SMPL-X
Generalized
NeurIPS 2025
null
Abstract#
We tackle the task of recovering an animatable 3D human avatar from a single or a sparse set of images. For this task, beyond a set of images, many prior state-of-theart methods use accurate “ground-truth” camera poses and human poses as input to guide reconstruction at test-time. We show that pose-dependent reconstruction degrades results significantly if pose estimates are noisy. To overcome this, we introduce NoPo-Avatar, which reconstructs avatars solely from images, without any pose input. By removing the dependence of test-time reconstruction on human poses, NoPo-Avatar is not affected by noisy human pose estimates, making it more widely applicable. Experiments on challenging THuman2.0, XHuman, and HuGe100K data show that NoPo-Avatar outperforms existing baselines in practical settings (without ground-truth poses) and delivers comparable results in lab settings (with ground-truth poses).
PaperApproach#
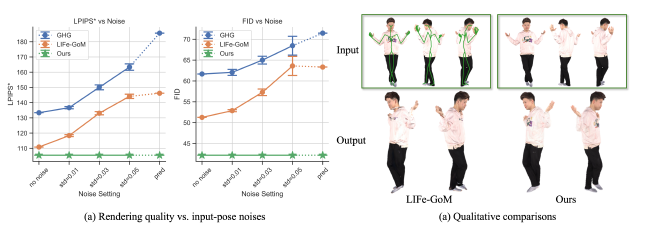
NoPo-Avatar teaser.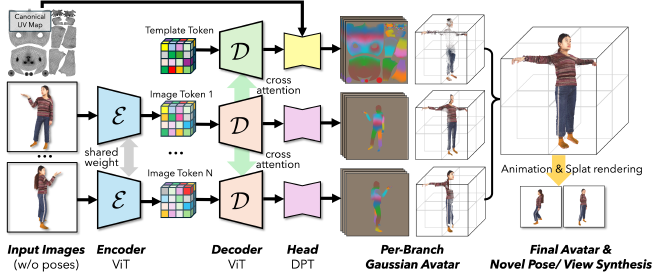
NoPo-Avatar overview.Results#
Data#
![]()
![]()
![]()
Comparisons#
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Papers Published @ 2025 - This article is part of a series.
Part 27: This Article