UVA
UVA: Towards Unified Volumetric Avatar for View Synthesis, Pose rendering, Geometry and Texture Editing#
Jinlong Fan, Jing Zhang, Dacheng Tao
NeRF
SMPL
CVPR 2023
Abstract#
Neural radiance field (NeRF) has become a popular 3D representation method for human avatar reconstruction due to its high-quality rendering capabilities, e.g., regarding novel views and poses. However, previous methods for editing the geometry and appearance of the avatar only allow for global editing through body shape parameters and 2D texture maps. In this paper, we propose a new approach named Unified Volumetric Avatar (UVA) that enables local and independent editing of both geometry and texture, while retaining the ability to render novel views and poses. UVA transforms each observation point to a canonical space using a skinning motion field and represents geometry and texture in separate neural fields. Each field is composed of a set of structured latent codes that are attached to anchor nodes on a deformable mesh in canonical space and diffused into the entire space via interpolation, allowing for local editing. To address spatial ambiguity in code interpolation, we use a local signed height indicator. We also replace the view-dependent radiance color with a pose-dependent shading factor to better represent surface illumination in different poses. Experiments on multiple human avatars demonstrate that our UVA achieves competitive results in novel view synthesis and novel pose rendering while enabling local and independent editing of geometry and appearance.
PaperApproach#
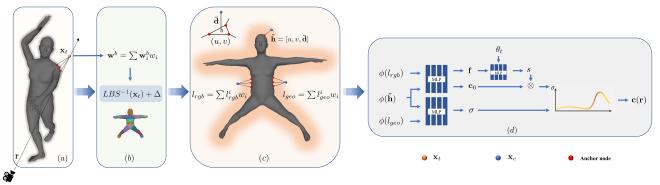
UVA overview.Results#
Data#
Comparisons#
![]()
![]()
![]()
![]()
![]()
Performance#
![]()
![]()
Papers Published @ 2023 - This article is part of a series.
Part 6: This Article