Vid2Avatar
Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition#
Chen Guo, Tianjian Jiang, Xu Chen, Jie Song, Otmar Hilliges
NeRF
SMPL
SDF
Monocular
CVPR 2023
null
Abstract#
We present Vid2Avatar, a method to learn human avatars from monocular in-the-wild videos. Reconstructing humans that move naturally from monocular in-the-wild videos is difficult. Solving it requires accurately separating humans from arbitrary backgrounds. Moreover, it requires reconstructing detailed 3D surface from short video sequences, making it even more challenging. Despite these challenges, our method does not require any groundtruth supervision or priors extracted from large datasets of clothed human scans, nor do we rely on any external segmentation modules. Instead, it solves the tasks of scene decomposition and surface reconstruction directly in 3D by modeling both the human and the background in the scene jointly, parameterized via two separate neural fields. Specifically, we define a temporally consistent human representation in canonical space and formulate a global optimization over the background model, the canonical human shape and texture, and per-frame human pose parameters. A coarse-to-fine sampling strategy for volume rendering and novel objectives are introduced for a clean separation of dynamic human and static background, yielding detailed and robust 3D human geometry reconstructions. We evaluate our methods on publicly available datasets and show improvements over prior art.
PaperApproach#
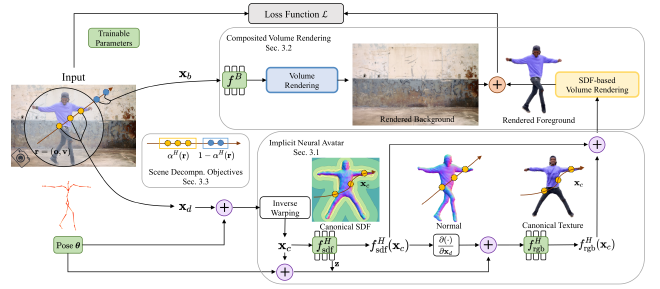
Vid2Avatar overview.Results#
Data#
![]()
![]()
Comparisons#
![]()
![]()
Performance#
![]()
![]()
Papers Published @ 2023 - This article is part of a series.
Part 5: This Article